 by
by by Rudy Omri
Twitter | LinkedIn | Website | Department Page
Carmen Hill’s lecture last week gave me a few valuable takeaways: it is important to look for collaboration opportunities, to always learn from other disciplines and to not stay within your comfort zone. As research becomes more integrative and global, collaboration is becoming more important, and social media analysis in the academic community can provide invaluable collaboration prospects. I am currently working on an MS in Geography, but I am always interested in doing interdisciplinary work. For my master’s thesis, I am researching about spatial variability of social media representativeness through opinion mining and I am hoping to incorporate various approach from different fields of study. My research spans across multiple disciplines – spatial variability concerns about geography, social media is part of journalism and communication, representativeness and public opinion are mostly sociology, and most methods that I am using revolve around computer science. The realization about the importance of breadth is the reason why I am taking this course. I just feel that it is about time for me to go out, look for things that I can learn from others and incorporate them in my research. I believe that graduate students must not limit their perspectives only within the scope of their field and it is important to attain a wide range of skill sets.
. . . . . . .
In this post, I would like to share with you a method that I use for my research: opinion mining/sentiment analysis. Not all social media aficionados could afford thousands of dollars to conduct a high quality Twitter analysis. But, with a little programming background and some free time to be spent on GitHub, you can actually do Twitter analysis on your own. Twitter offers an analytic feature called the Streaming API that lets you follow a sample of the entire stream in real time. This process is typically known as “tweetcrawling.”

Almost all programming languages are capable of streaming public tweets. Each tweet has its own metadata that contains username, user ID, location, geographic coordinates, time & date, and of course, the tweet. This is what tweetcrawling looks like using Python programming language:
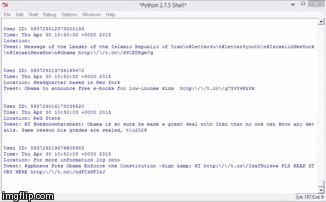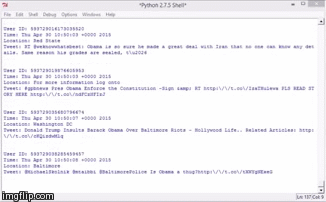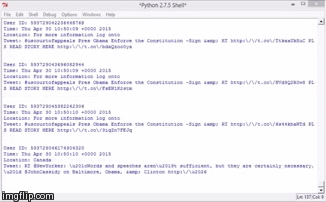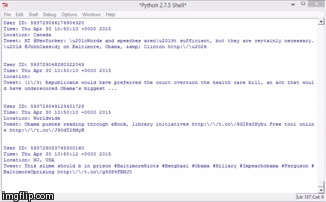
If you notice, all the tweets in the stream contain the word “Obama”. This is because I filtered the tweets based on the keyword Obama (my master’s thesis is about social media sentiments on President Obama).
A simple Twitter research usually employs sentiment analysis to study polarity of opinions. Sentiment analysis refers to the process of determining how people on Twitter think or feel about an issue. Sentiment analysis uses natural language processing, text analysis and computational linguistics to identify and extract subjective information in tweets. Typically, sentiment analysis depends on “prebaked dictionaries” – or the fancy term that social media researchers love to use: “lexicon” – that contain almost every opinion-related word in English language and each word has its own encoded, predetermined polarity score. To keep it simple, the sum of the polarity scores for each tweet determines the sentiment of that tweet. Negative scores suggest negative sentiments, zero scores indicate neutrality, and positive scores indicate positive opinions.
For example:
Let’s assume these words have these encoded scores:
Hate: -3
Love: +3
And for some arcane reason you choose to analyze a tweet that talks about Chipotle.
“As a Chipotle lover, I hate anyone who hates burrito.”
The simplest way to calculate the score would be:
Lover (+3) + hate (-3) + hates (-3) = -3 = negative sentiment
Obviously it is way more complicated than this (analysts must take sarcasm, expressions and multilingual tweets into account), but I hope this example gives you an idea of how sentiment analysis works.
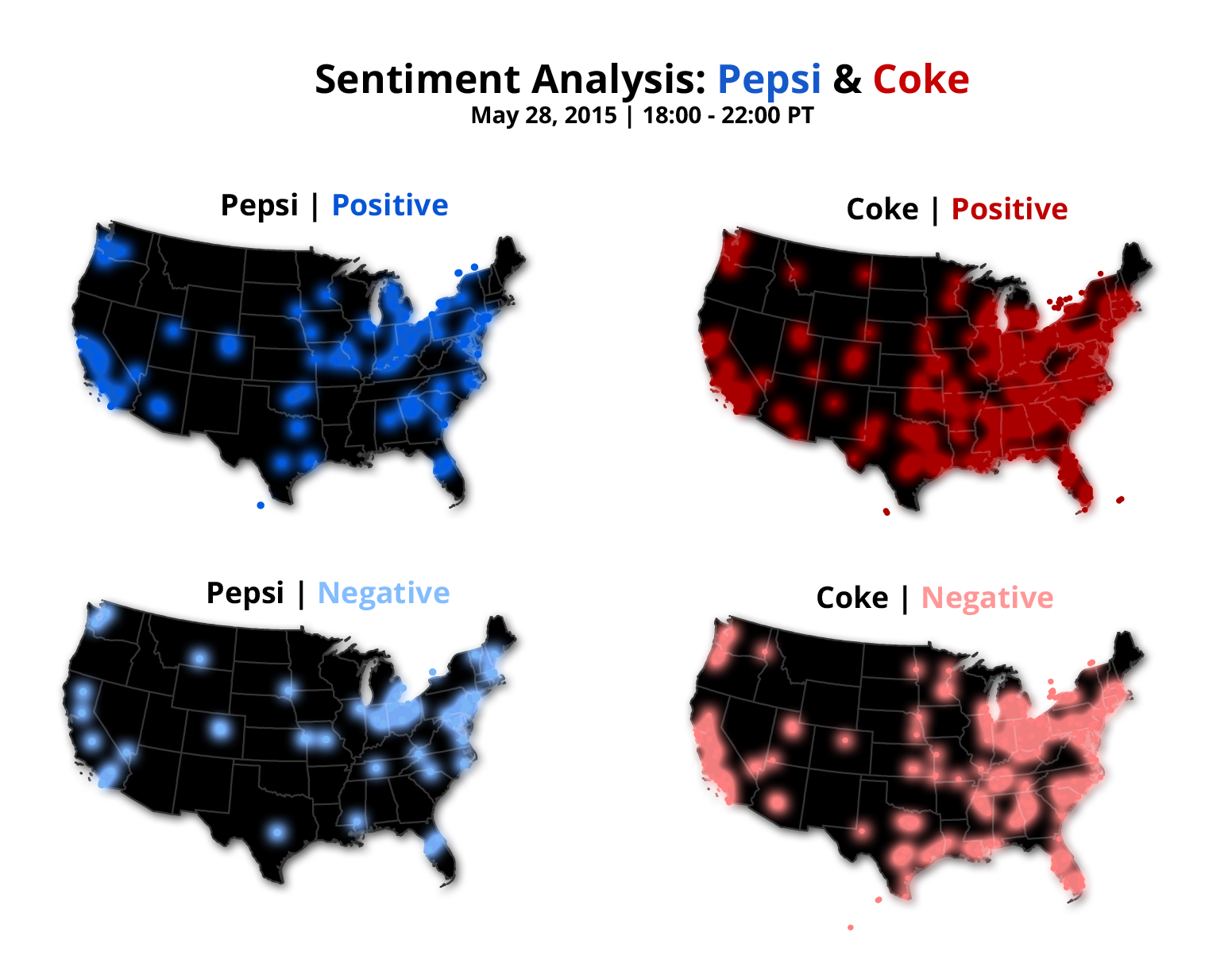
After all the sentiments are determined, researchers aggregate the results and conduct a more advanced, complex analysis. This is where the heavier statistical and quantitative analysis come into play. As a geographer/cartographer, I love making Twitter sentiment maps. Maps are a great way to visualize a phenomenon, including tweets. Here’s one of the maps that I just made. This map shows the polarity of Twitter sentiments for both Coke & Pepsi some time last week.
Rudy Omri
@rudyomri


Really interesting post, Rudy! I love that you’re expanding your knowledge. I agree that not limiting ourselves in our comfort zone is the best way to gain more knowledge and have greater appeal when looking for jobs. I’ve been considering taking some coding classes because, even though I have zero expertise in the matter, it is something that would make me a more appealing PR candidate and an overall well-rounded professional. Good luck on your senior thesis, it sounds really interesting!
Rudy,
Wow, this was very in-depth. I found it quite interesting how one can go about calculating negativity/positivity sentiment in a post. Such analyzation could be very useful. You say, “Maps are a great way to visualize a phenomenon, including tweets”, and I’ve never really thought of it that way. But your Coke/Pepsi maps are very telling, and I can see their potential in analyzing large amounts of data.
I agree with what Carmen said about not getting too stuck in your own discipline. I think that is part of why I love PR so much is because we are constantly learning and absorbing new information. Part of our industry is understanding and communicating with other industries so I find that to be so valuable. I love how you merged different disciplines into this post, I feel like I learned something new.